Roman Kamushken
This article reads the public benchmark data as an industry observer, not an advocate. The goal is a working reference for anyone weighing a cheaper alternative to OpenAI and Claude, the kind of comparison an engineering lead pulls up before approving a budget. No ideology, no claims that one country builds better software than another. Just the numbers that are visible right now, the trade-offs they hide, and the conditions under which a switch holds up.
The cost gap is real, the quality gap is narrower than expected
The most useful framing comes from a six-task breakdown that maps each common AI workload to its strongest Western baseline and its closest Chinese counterpart. Aggregated across those tasks, recent industry observations point to an operating cost reduction near 87% with an average quality decrease around 4%, and no significant revenue impact reported by teams running the comparison.
Those two figures sit in tension. A 4% average quality decrease sounds trivial. An 87% cost reduction sounds too good to ignore. The honest reading lives between them. Averages flatten the one place where the gap is wide, and that place happens to be the task many product teams care about most.
Before trusting any aggregate, it helps to see the per-task structure. The average is an average of very different gaps, from near-parity in some workloads to a meaningful deficit in others.
Task by task, which Chinese model replaces which
The table below maps each workload to its Western baseline and the Chinese model that lands closest on quality, with the approximate quality gap and cost multiple reported in mid-2026 benchmark data.
| Task type | Western baseline | Chinese alternative | Provider | Quality gap | Cost saving |
|---|---|---|---|---|---|
| Reasoning | Claude Opus 4.8 | Kimi K2.7 | Moonshot AI | ~8% | ~11x cheaper |
| Code generation | GPT-5.5 | Qwen 3.7 Max | Alibaba | ~18% | ~7x cheaper |
| Agent loops | Claude Sonnet 4.7 | GLM 5.2 | Zhipu AI | ~3% | ~5x cheaper |
| Bulk generation | GPT-5.5 mini | MiMo V2.5 | Xiaomi | ~6% | ~12x cheaper |
| Image | GPT-Image-2 | Wan 2.5 | Alibaba | ~5% | ~8x cheaper |
| Video | Sora 2 | Kling 3.0 | Kuaishou | roughly equal | ~6x cheaper |
A few patterns deserve attention. Agent loops show the smallest gap at around 3%, which matters because agentic orchestration is where token spend balloons fastest. A 5x saving on the highest-volume task type compounds quickly across a month of automated runs. Bulk generation tells a similar story, with MiMo V2.5 trailing by about 6% while costing roughly a twelfth of its baseline. Several of these alternatives, including Qwen and GLM, are open-weight and reachable through a single access point like Venice.ai, which makes a hands-on check feasible before any of these numbers are taken on faith.
Video is the surprise. Kling 3.0 lands at rough parity with Sora 2 on quality while costing about six times less. For teams producing short-form motion at scale, that is the line item that changes a quarterly budget.
Then there is code. Qwen 3.7 Max is about 7x cheaper than GPT-5.5, yet it trails by roughly 18%, more than four times the gap of any other task in the set. That number is the entire argument for caution, and it earns its own section.
Where the 18% code gap actually hurts
An 18% quality deficit on code generation is not a rounding error. The practical question is where that gap converts into real cost, because it does not bite evenly across every kind of programming work.
It hurts most in:
→ Production-critical code paths where a subtle logic error reaches users before review catches it
→ Complex refactors that touch many files and depend on holding a large mental model of the codebase
→ Security-sensitive logic, auth flows, and payment handling where a plausible-looking mistake is expensive
→ Long, multi-step generation where small errors accumulate and the model loses the thread
It barely registers in:
→ Throwaway prototypes and spikes meant to be read once and discarded
→ Boilerplate scaffolding, config files, and repetitive CRUD endpoints
→ Test stubs and fixtures where a human reviews everything anyway
→ Bulk transformations across many small, independent snippets
The pattern is consistent across teams reporting their results. The 18% gap is survivable when a human stays in the review loop and the blast radius of a mistake is small. It becomes a liability the moment generated code ships with light oversight into a system where failure is costly. A team that routes prototypes to Qwen and keeps GPT-5.5 for the production-critical 20%, the code that actually ships to users and influences user experience, often captures most of the saving while absorbing little of the risk.
This is why the aggregate 4% figure is honest but incomplete. If your workload is code-heavy and your review process is thin, your effective quality decrease is closer to that 18% than to the comfortable average.
Reading the intelligence-vs-cost map
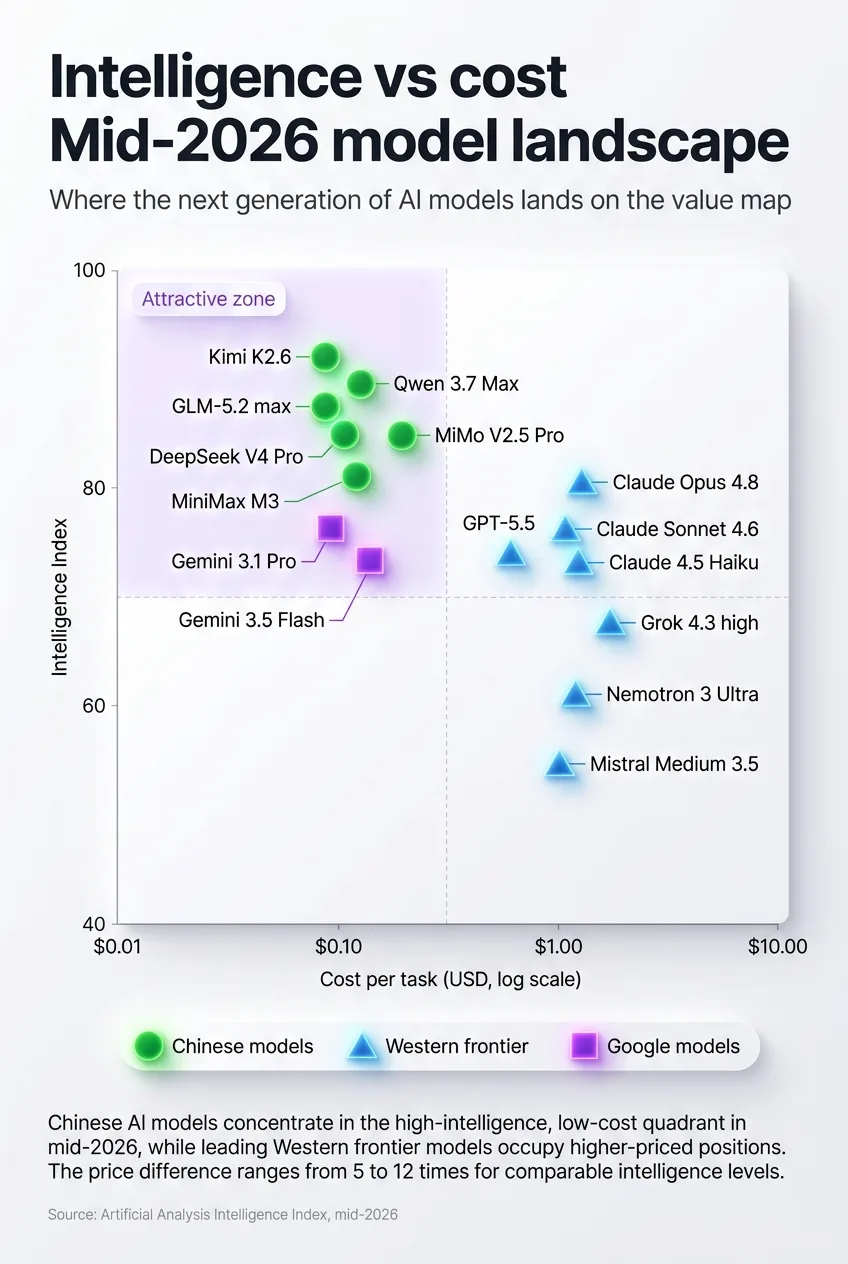
The six-task table answers which model to pick per job. A second view, the intelligence-versus-cost map published by independent benchmark trackers, answers a broader question about where the whole market sits in mid-2026.
Source: Artificial Analysis Intelligence Index, mid-2026.
The attractive quadrant is the one every buyer wants, high measured intelligence paired with low cost per task. As of mid-2026, that zone is crowded with Chinese models. MiMo V2.5 Pro, DeepSeek V4 Pro, Kimi K2.6, MiniMax M3, GLM-5.2 max, and three Qwen variants, including Qwen 3.7 Max and Qwen 3.5 397B A17B, all land there. The Western presence in that same low-cost, high-intelligence corner is thinner, anchored mainly by Gemini 3.1 Pro Preview and Gemini 3.5 Flash.
The expensive zone reads almost like a roll call of the frontier labs. GPT-5.5 high, Claude Opus 4.8 max, Claude Sonnet 4.6 max, Claude 4.5 Haiku, GPT-5.4 mini, Grok 4.3 high, Nemotron 3 Ultra, and Mistral Medium 3.5 cluster where cost per task runs high. Some of these models top the intelligence axis. The point of the map is that they are no longer alone at the top, and their pricing assumes a scarcity that the lower-left quadrant is steadily eroding.
Two readings follow. The optimistic one says buyers now have genuine choice on the efficient frontier, with several models offering most of the intelligence at a fraction of the price. The cautious one notes that the very highest intelligence scores still sit in the expensive zone, so the most demanding reasoning and code work may still justify a premium model.
Both readings can be true at once, which is exactly why per-task routing beats picking a single house model.
The offshoring parallel and compute as a product
There is a useful historical analogy for what the cost data describes, and it comes from manufacturing rather than software. In the 1990s, Western firms offshored production to cut unit costs dramatically. The early results looked like pure margin, much like an 87% reduction looks today. The lessons that followed are worth borrowing.
The first lesson is about know-how. Offshoring the build step was cheap, but the firms that retained design, architecture, and quality control kept their leverage. The ones that outsourced the thinking along with the assembly slowly lost the ability to evaluate their own suppliers. Applied to AI, the parallel is direct. Routing generation to a cheaper model is the assembly step. The architecture decisions, the review standards, and the judgment about what good output looks like are the know-how. Keep those in-house and a cheap model is a tool. Surrender them and the cost saving turns into dependence.
The second lesson is about intellectual property. Sending designs to an external producer always carried some IP exposure, and managing that exposure became a discipline of its own. Compute behaves the same way. When prompts, proprietary code, and internal data flow to a hosted model, they leave your boundary. That risk is manageable, and the next section covers the concrete levers, but pretending it does not exist is how the offshoring era produced its expensive surprises.
Compute, in other words, is becoming a commodity input the way contract manufacturing once did. Commodities get cheaper and more interchangeable over time, which is good for buyers.
The durable advantage shifts to whoever holds the design taste and the quality bar, not to whoever runs the cheapest inference.
Self-hosting, data sovereignty and regulatory risk
One structural difference separates much of the Chinese model landscape from the leading Western APIs. Many of the strongest Chinese models ship with open weights, and that single fact reshapes the risk calculation.
Open weights mean self-hosting is on the table. A team can run the model inside its own infrastructure, which keeps prompts and proprietary data from ever reaching a third-party provider. For organizations with strict data sovereignty requirements, whether regulated industries or internal tooling that touches sensitive code and customer records, that control is often worth more than the raw price difference. The cost comparison and the privacy argument point the same direction here.
Self-hosting also enables local fine-tuning. A model can be adapted to a domain on private data without sending a single training example outside the organization. Teams that depend on a closed API for tuning give up exactly that boundary. With open weights, the boundary stays intact.
Regulatory exposure is the third factor, and it cuts in an unexpected direction. A hosted API is a single point of policy failure. If a provider changes terms, restricts a region, or faces its own regulatory pressure, dependent teams have little recourse. A self-hosted open-weight model carries a lower risk of sudden access loss, because the weights already sit on infrastructure the team controls. None of this erases the geopolitical and compliance questions that come with the provenance of any model, and those deserve real diligence. The structural point stands.
Owning the weights converts a vendor relationship into an asset you hold.
A practical migration checklist
Migration is not free, and any honest reference says so plainly. The teams that capture the cost saving without inheriting the quality risk tend to follow a disciplined sequence rather than a wholesale swap. The table below outlines a defensible path.
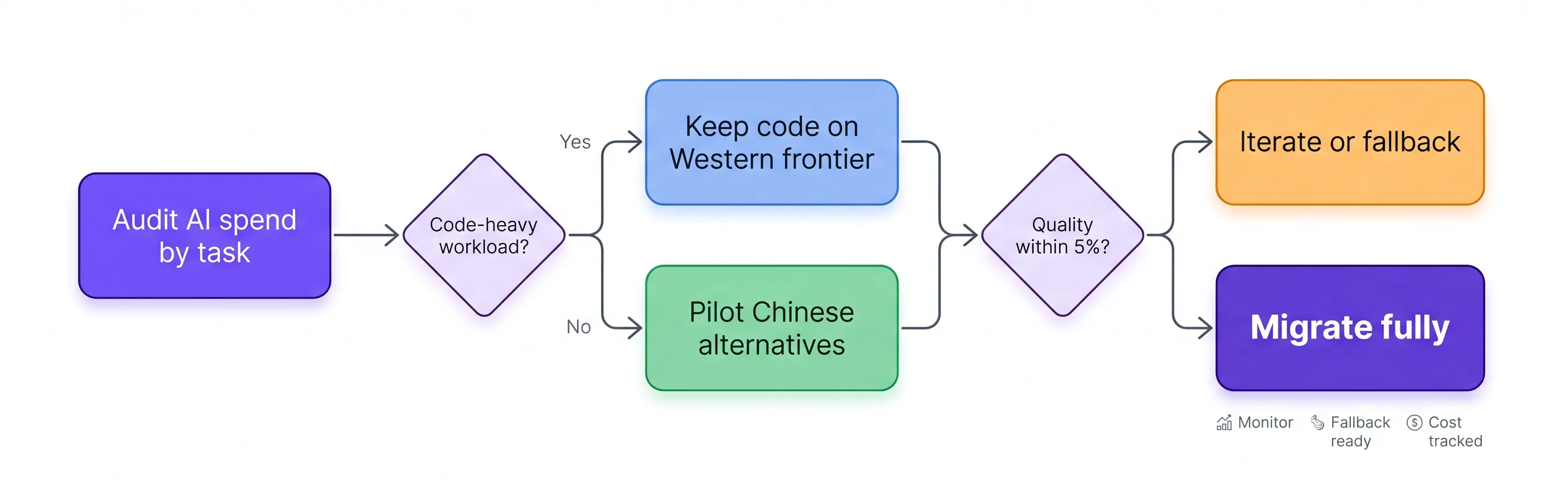
| Step | Action | What to verify |
|---|---|---|
| 1. Audit by task | Sort current AI spend into the six task types | Which workloads dominate cost, and which are code-critical |
| 2. Start where the gap is smallest | Pilot agent loops, bulk, and video first | Quality holds within tolerance on real traffic, not demos |
| 3. Keep a Western fallback for code | Route production-critical code to GPT-5.5 | The 18% gap never reaches a path with thin review |
| 4. Measure on your own data | Run a side-by-side on representative prompts | Benchmarks generalize to your domain, not just public sets |
| 5. Decide on hosting | Choose hosted API or self-hosted open weights | Data sovereignty and fine-tuning needs are met |
| 6. Instrument quality | Add automated checks and human review gates | Regressions surface before users see them |
The order matters. Starting with the low-gap, high-volume tasks captures most of the saving early and builds confidence on workloads where the downside is small. Code stays on a frontier model until the team has hard evidence, from its own data, that a cheaper alternative clears the bar. A migration that begins by ripping out the production code model is the one that generates the cautionary blog post six months later.
One more discipline belongs here. Measure on your own prompts, not on published benchmark sets. Public scores are a starting hypothesis. Your domain, your prompt style, and your tolerance for error are the actual test, and they routinely shift the apparent gap in either direction.
Where a privacy-first gateway fits
Testing several models against your own workload raises a practical problem. Signing up for each provider, managing separate keys, and routing prompts to compare outputs is friction, and for teams with data sensitivity it also multiplies the number of places your prompts travel.
A privacy-first gateway that exposes multiple models behind one interface reduces both problems. Venice.ai is one such option, offering access to a range of models, including open-weight Chinese ones like Qwen, while not storing prompts or generation history. For the evaluation phase described above, that combination is convenient, because it lets a team run the same prompt across alternatives quickly without scattering proprietary inputs across half a dozen vendor logs. If you want the longer rationale for a privacy-focused approach to model access, the guide to private and uncensored AI tools covers it in depth, and the breakdown of AI chat interface design is a useful companion for anyone building on top of these models.
Treat this as a tooling note rather than a verdict. The architecture of the comparison matters more than the gateway used to run it. The point is that the friction of multi-model evaluation has a straightforward fix, and removing that friction is what makes a disciplined, data-driven migration realistic rather than aspirational.
Frequently asked questions
Are Chinese AI models actually cheaper than GPT and Claude? Yes, and the gap is large. Across the six common task types, mid-2026 benchmark data shows Chinese alternatives running roughly 5x to 12x cheaper than their Western baselines, with an aggregate operating cost reduction near 87% on a typical mixed workload, according to the Artificial Analysis Intelligence Index for mid-2026.
Is Qwen as good as GPT-5.5 for coding? Almost, with one caveat. Qwen 3.7 Max trails GPT-5.5 by about 18% on code generation, the widest quality gap in the entire comparison. It is well suited to prototypes, boilerplate, and reviewed work, and less suited to shipping production-critical code with light oversight.
Where is the quality gap smallest? Agent loops show roughly a 3% gap, and video sits at near parity. These are the workloads where a switch captures most of the cost saving with minimal quality risk, which is why a staged migration usually starts there.
Can I self-host Chinese AI models? Many of the strongest ones ship with open weights, so yes. Self-hosting keeps prompts and proprietary data inside your own infrastructure, enables local fine-tuning without sending data to a provider, and lowers the risk of sudden access loss compared with a closed API.
Is migrating away from OpenAI or Claude safe? It is safe when staged. Audit spend by task, pilot the low-gap workloads first, keep a Western fallback for production code, and measure on your own data before committing. The risk comes from wholesale swaps, not from a measured, evidence-led transition.
What is the simplest way to compare models before switching? Run the same representative prompts across candidates and judge the output against your own quality bar. A privacy-first gateway like Venice.ai makes that side-by-side faster without scattering your prompts across multiple vendor logs.
The snapshot as of mid-2026
This is a moment-in-time reading, and the numbers will move. As of June 2026, the structure is clear enough to act on. Chinese AI models offer a real and large cost advantage, a quality gap that is narrow on most tasks and wide on one, and an open-weight option that turns hosting into a strategic choice rather than a vendor lock.
The disciplined play is not all-or-nothing. Route the high-volume, low-gap tasks to the cheaper models and bank the saving. Keep production-critical code on a frontier model until your own data says otherwise. Treat compute as the commodity it is becoming, and hold on to the design judgment and review standards that no model replaces. Teams that read the gap per task rather than per headline are the ones that capture the upside without buying the risk. For anyone funding model spend with crypto and watching margins closely, the companion piece on paying for Claude Pro with USDT is a useful next read.